Introduction
The last year has witnessed a divergence in the capabilities of large language models. Closed-source proprietary systems (GPT-5, Gemini 3.0 Pro, Claude Opus 4) have steadily pushed the boundaries of reasoning and agentic performance1, while open-source alternatives have struggled to keep pace. Even more concerning, a widening gap has emerged between industry and academia, threatening to concentrate resources and frontier AI capabilities within a handful of well-capitalized organizations2.
DeepSeek V3.2 models challenge this trajectory.
On December 1st, 2025, DeepSeek released two models that fundamentally reshape the open-source landscape: DeepSeek V3.2, a balanced 685-billion parameter model achieving GPT-5-level performance, and DeepSeek V3.2-Speciale, an extended-reasoning variant that rivals Gemini 3.0 Pro. Both models are released under an MIT license with complete technical documentation and open weights on Hugging Face—no restrictions, no API-only access, no commercial limitations.
The performance claims are backed by unprecedented competitive results. V3.2-Speciale achieves gold-medal performance across multiple 2025 international competitions: 35 out of 42 points on the International Mathematical Olympiad (IMO), 492 out of 600 on the International Olympiad in Informatics (IOI), and successfully solves 10 out of 12 problems at the ICPC World Finals. These aren't incremental improvements; they represent the first open-source model to reach gold-medal thresholds in these elite competitions—domains previously dominated by proprietary systems with orders of magnitude more resources.
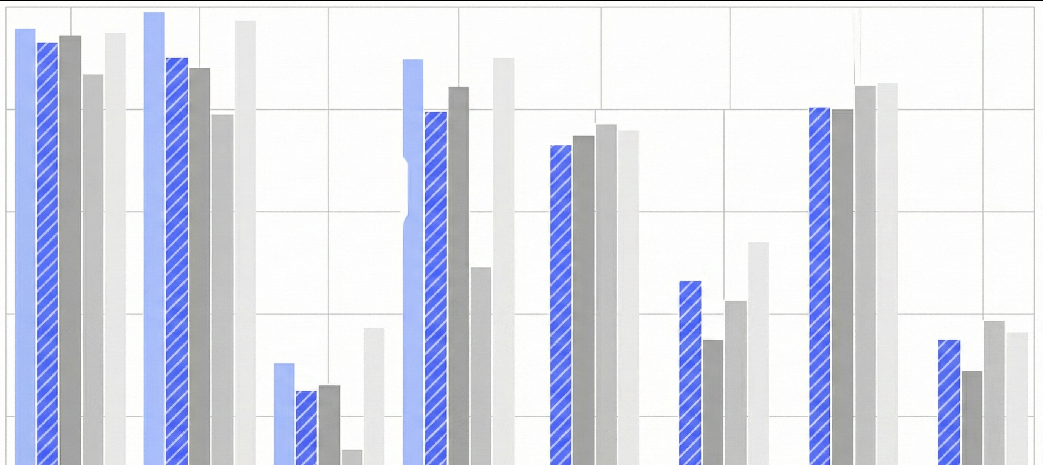
Perhaps most striking is the cost efficiency. At $0.42 per million output tokens, DeepSeek V3.2 operates at approximately 24× lower cost than GPT-53 ($10.00/M tokens), 29× lower cost than Gemini 3 Pro4 ($12.00/M tokens), and significantly lower than many other frontier models.
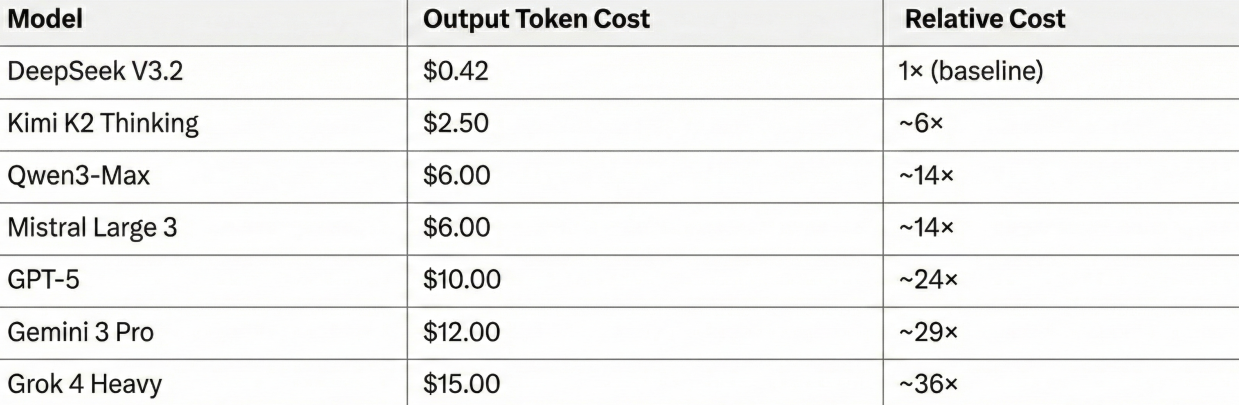
Table 1: Output Token Cost Comparison (per 1M tokens). For contexts ≤ 200K tokens; higher for longer contexts.
The release raises a critical question: How did an open-source effort close what many believed was an insurmountable gap? The answer lies in three key innovations: a novel sparse attention mechanism that reduces computational complexity from quadratic to near-linear, a massive investment in reinforcement learning post-training exceeding 10% of pre-training compute, and an automated pipeline for synthesizing 1,827 distinct agentic task environments. This represents fundamental advances in how we approach reasoning-first model design.
This post examines the technical foundations of DeepSeek V3.2, analyzes its performance across benchmarks and competitions, and explores what this release means for the trajectory of open-source AI. The implications extend beyond a single model release: DeepSeek V3.2 demonstrates that with principled architectural choices and strategic resource allocation, open-source models can achieve—and in some cases exceed—the capabilities of proprietary frontier systems.
What Makes This Release Different
Three factors distinguish DeepSeek V3.2 from prior open-source releases and position it as a genuine alternative to proprietary frontier models.
Full Open-Source Commitment
DeepSeek-V3.2 fundamentally challenges the prevailing narrative that open-source models are consistently "eight months behind" proprietary frontiers56. By releasing the full open weights under an MIT license, the model enables complete commercial utility rather than restricting capabilities to research silos. This release marks a historic milestone: it is the first open-source model capable of achieving gold-level performance in the IMO 2025, CMO 2025, IOI 2025, and the ICPC World Finals. The release is accompanied by a comprehensive technical paper, offering complete transparency into the architecture and training recipes that power these results.
Economic Accessibility
High intelligence should not be cost-prohibitive. DeepSeek-V3.2 maintains the same accessible API pricing as its predecessor at $0.42 per million output tokens. This pricing structure represents a radical shift in the economics of deployment: it is approximately 30× cheaper than Gemini 3.0 Pro and 25× cheaper than GPT-5. This efficiency allows developers and enterprises to deploy frontier-class reasoning and agentic capabilities at scale, effectively democratizing access to state-of-the-art intelligence7.
Reasoning-First, Agent-Oriented Design
Unlike models that append reasoning modules as an afterthought, DeepSeek-V3.2 is built on a reasoning-first architecture. This approach draws on recent work demonstrating that extended reasoning—often termed "chain-of-thought"8 or "System 2" processing10—benefits from tight integration with the base model rather than auxiliary scaffolding. Reasoning is integrated directly into the core model, ensuring that "thinking" is intrinsic to every operation. This philosophy extends to the model's agent-oriented design; it was constructed from the ground up to handle complex tool-use scenarios.
- Integrated Thinking Mode: A native "thinking" mode is introduced within tool-use trajectories, allowing the model to reason, act, and self-correct fluidly.
- V3.2-Speciale: For tasks requiring maximum cognitive depth, the DeepSeek-V3.2-Speciale variant offers extended thinking capabilities, relaxing length constraints to solve the most intractable problems.
The Three Critical Bottlenecks
DeepSeek identified three fundamental limitations that have historically constrained open-source models compared to proprietary frontiers:
Architectural Inefficiency
The predominant reliance on vanilla attention mechanisms severely constrains efficiency for long sequence processing11. This complexity poses a substantial obstacle to both scalable deployment and effective post-training, particularly when processing the massive contexts required for reasoning1213.
Insufficient Post-Training Compute
While frontier models increasingly allocate trillions of tokens and months of compute to pre-training1415, open-source models typically suffer from insufficient computational investment during the post-training phase. This resource imbalance directly limits performance on hard tasks and complex reasoning benchmarks compared to closed-source counterparts.
Weak Agentic Generalization
In the context of AI agents, open models demonstrate a marked lag in generalization and instruction-following capabilities16. This deficiency hinders their effectiveness in real-world deployments where robust adaptation to diverse environments is required.
Technical Innovations
DeepSeek Sparse Attention (DSA)
The architectural bottleneck of long-context processing has constrained language models since the introduction of the transformer architecture11. Standard attention mechanisms compute relationships between every token pair in a sequence, resulting in complexity where is the sequence length. For a 128K token context—increasingly necessary for agentic workflows—this quadratic scaling becomes computationally prohibitive during both training and inference.
Various approaches have been proposed to mitigate this bottleneck: sliding window attention9, sparse attention patterns1718, low-rank approximations1920, learned sparsity2122, and conditional computation23. However, these approaches often face a fundamental trade-off: aggressive sparsification improves efficiency but degrades model quality, particularly on tasks requiring long-range dependencies24.
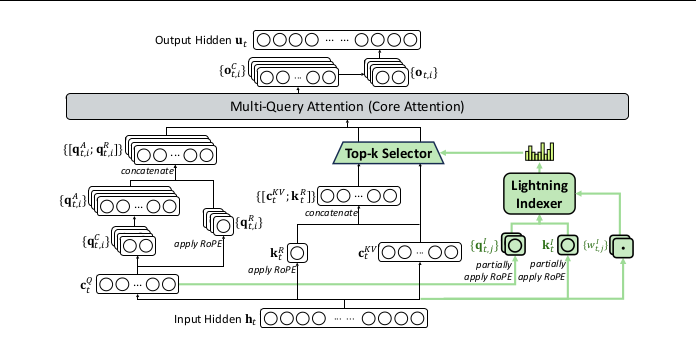
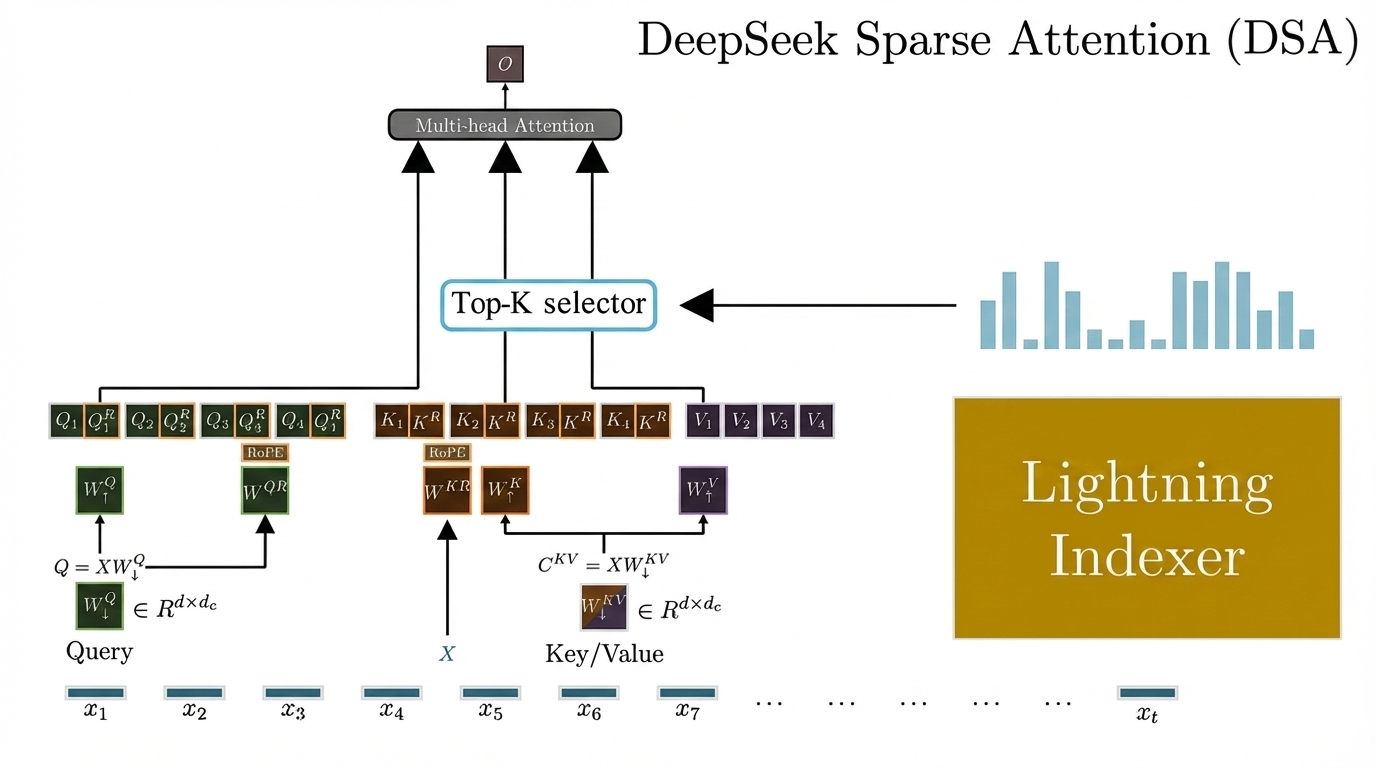
Figures 1 & 2: The complete DSA architecture instantiated under Multi-Head Latent Attention (MLA). The Lightning Indexer (highlighted in green) produces relevance scores for all preceding tokens, which feed into the Top-k Selector. Only the selected tokens—those with the highest index scores—proceed to the full multi-head attention computation.
DeepSeek Sparse Attention (DSA) shown in Figure 1 represents the first successful implementation of fine-grained sparse attention that maintains model quality while dramatically reducing computational requirements. DSA reduces attention complexity from to , where is a small constant (typically 2,048 tokens) that remains fixed regardless of sequence length. The key innovation is that this sparsification introduces virtually no degradation in model output quality while enabling substantial efficiency gains.
The Lightning Indexer Architecture
At the core of DSA is the Lightning Indexer (in green), a lightweight scoring mechanism that rapidly assesses which preceding tokens are relevant for computing attention at the current position (Figure 2). Rather than computing full attention across all historical tokens, the indexer evaluates relevance and selects only the top- most important tokens for the actual attention computation.
The indexer computes an index score between the current query token at position and each preceding token at position according to:
where denotes the number of indexer heads, and are query-derived vectors, and is the shared key vector from the preceding token. The ReLU activation enforces sparsity by immediately discarding negative scores, filtering out irrelevant tokens before the expensive attention computation begins.
Efficiency Through Quantization and Rotation
Computing index scores for every historical token still requires substantial computation at long sequence lengths. DSA achieves additional speedup through aggressive 8-bit quantization of the query and key vectors used in the indexer (Figure 3). Since the indexer's purpose is coarse relevance assessment rather than precise attention computation, lower precision suffices.
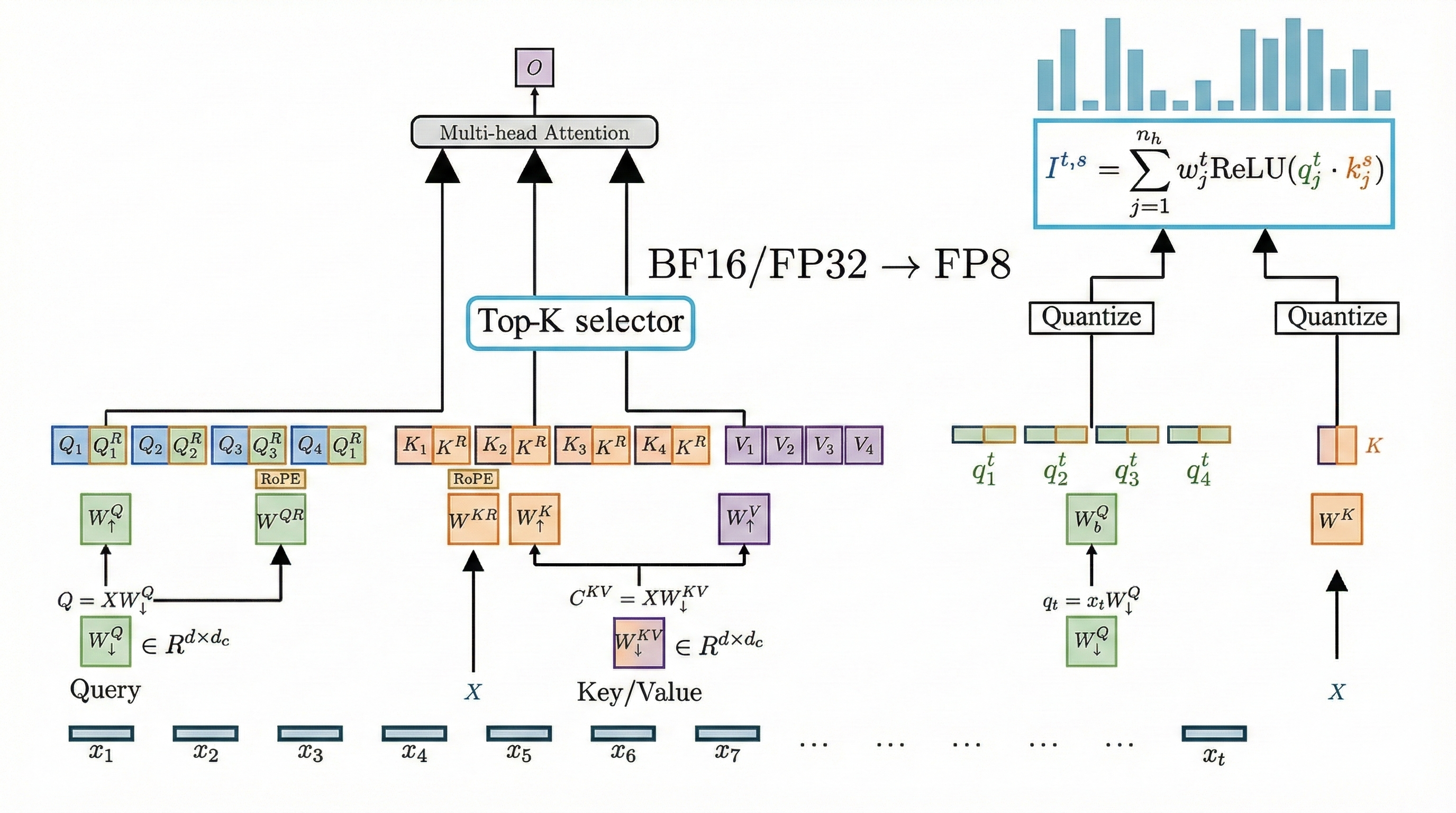
Figure 3: The quantization and rotation pipeline showing how the Fast Walsh-Hadamard Transform redistributes outlier values before 8-bit quantization.
However, naive quantization of floating-point vectors introduces a critical challenge: outlier values. Neural network activations often contain "spikes"—entries with magnitudes far exceeding the typical range. When these high-dynamic-range vectors are quantized to 8 bits, the outliers cause severe information loss because the limited precision cannot capture the full value spectrum.
DSA solves this through a deterministic rotation applied before quantization (Figure 4). Specifically, the Fast Walsh-Hadamard Transform rotates the vector space, redistributing the outlier values across all dimensions. This transformation "mixes" the large spikes throughout the vector, producing a more uniform distribution that 8-bit quantization can represent accurately. Crucially, the Hadamard transform requires only additions and subtractions—no expensive matrix multiplications—making it extremely efficient to compute.
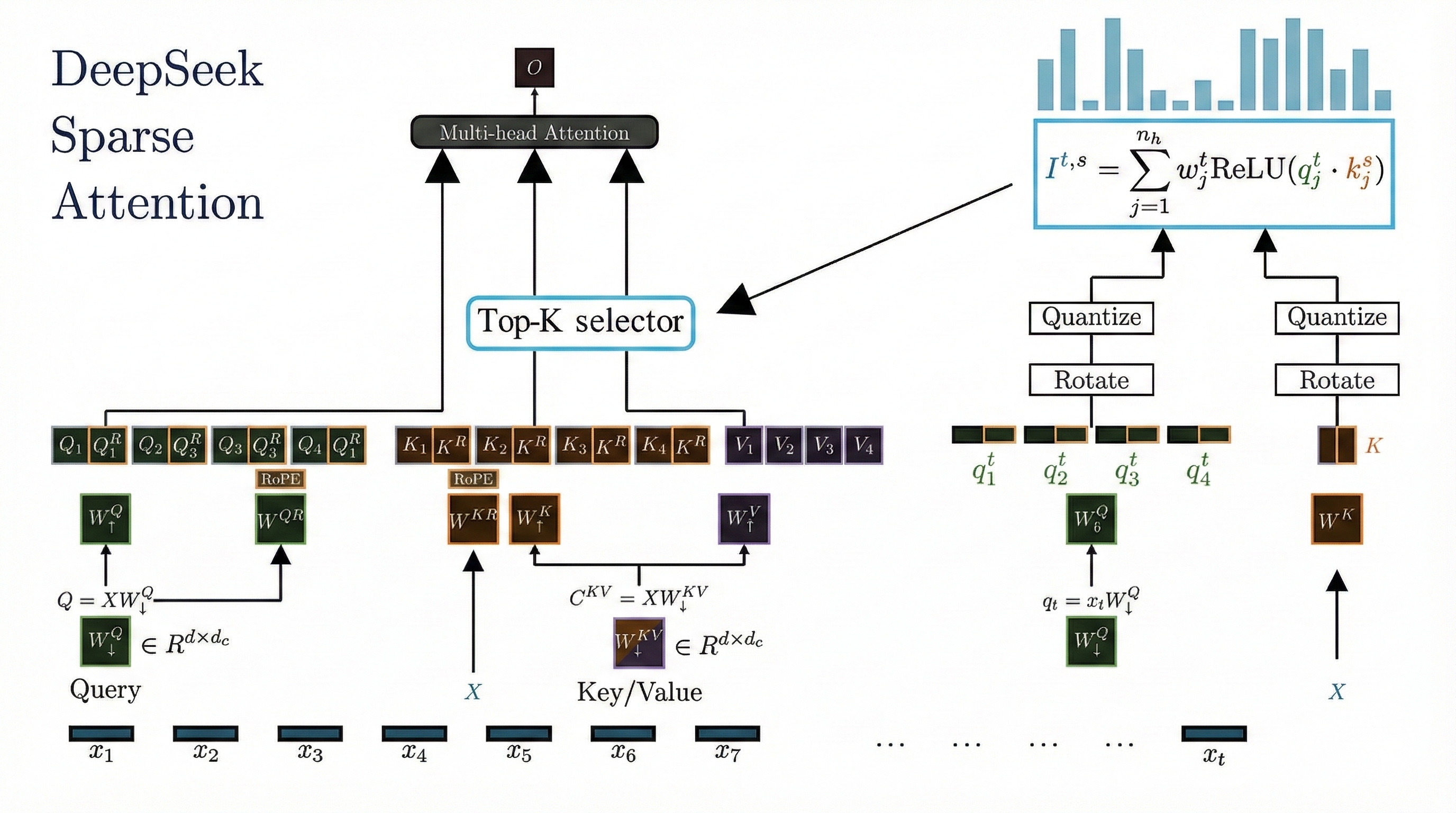
Figure 4: The Fast Walsh-Hadamard Transform redistributes outlier values across all dimensions before quantization, enabling accurate 8-bit representation.
Training Methodology: From Dense to Sparse
Transitioning a pre-trained dense attention model to sparse attention requires careful training to ensure the Lightning Indexer learns to select the same tokens the full dense model would consider important. DeepSeek employs a two-stage training approach over approximately 1 trillion tokens of continued pre-training.
Dense Warm-up Stage: The model begins with all parameters frozen except the Lightning Indexer. The indexer is trained for 1,000 steps (2.1B tokens) to match the aggregated attention distribution of the full dense model. For each query token at position , the dense attention scores are summed across all heads and L1-normalized to produce a target distribution . The indexer is optimized to minimize the KL divergence between its output and this target:
This warm-up initializes the indexer to approximately replicate the dense attention pattern before any model parameters adapt to sparsity.
Sparse Training Stage: After warm-up, the fine-grained token selection mechanism activates, and all model parameters train jointly for 15,000 steps (943.7B tokens). The model now attends only to the top-k (2,048) selected tokens per query. A critical implementation detail: the indexer input is detached from the main computational graph, allowing separate optimization. The indexer continues to minimize its KL divergence loss on the selected token set, while the main model optimizes only the language modeling objective. This separation prevents training instabilities that arise when the indexer and main model interfere with each other's gradients.
Impact and Deployment
The efficiency gains from DSA are substantial. By reducing attention complexity to with k=2,048 selected tokens, the model achieves significant throughput improvements on long contexts. This architectural foundation enables the massive reinforcement learning post-training investment—exceeding 10% of pre-training compute—that drives V3.2's reasoning capabilities. Without DSA's efficiency gains, such extensive post-training would be computationally infeasible.
Perhaps most remarkably, DSA introduces this efficiency with no measurable quality degradation. The sparse attention mechanism produces virtually identical outputs to dense attention while dramatically reducing computational requirements. This achievement—fine-grained sparsity without quality loss—represents a genuine architectural breakthrough, enabling both the extended 128K context windows and the scaled test-time compute necessary for complex agentic workflows.
Massive RL Post-Training
While architectural efficiency enables long-context processing, architecture alone cannot deliver frontier reasoning capabilities. The second critical innovation in DeepSeek V3.2 is an unprecedented allocation of computational resources to the post-training phase—exceeding 10% of the pre-training compute budget. This investment, combined with novel techniques for stabilizing reinforcement learning at scale, directly drives the model's GPT-5-level reasoning performance.
Specialist Distillation Framework
Rather than training a single model on all tasks simultaneously, DeepSeek employs a specialist distillation approach2526. This approach shares conceptual similarities with mixture-of-experts training27 and ensemble distillation28, but differs in its execution: the training pipeline first develops dedicated expert models for six specialized domains, each fine-tuned from the same pre-trained DeepSeek-V3.2 base checkpoint:
- Mathematics
- Programming
- General logical reasoning
- General agentic tasks
- Agentic coding
- Agentic search
Each domain supports both thinking mode (extended chain-of-thought reasoning, as explored in2930) and non-thinking mode (direct response generation), with separate models generating training data for each modality. The specialists undergo large-scale reinforcement learning training to maximize performance in their respective domains. Once prepared, these specialist models generate domain-specific training data that is distilled into the unified V3.2 model.
This approach yields models that achieve performance only marginally below domain-specific specialists, with the performance gap effectively eliminated through subsequent mixed RL training. The distillation framework allows the final model to benefit from the concentrated expertise of multiple specialists while maintaining generality across all domains.
Mixed RL Training with Group Relative Policy Optimization
DeepSeek V3.2 employs Group Relative Policy Optimization (GRPO), introduced in prior DeepSeek work3132, as its reinforcement learning algorithm. GRPO builds on the policy gradient framework3334 and shares design elements with Proximal Policy Optimization35 and REINFORCE variants36. Merging reasoning, agent, and human alignment training into a single RL stage. This unified approach balances performance across diverse domains while avoiding the catastrophic forgetting that plagues multi-stage training paradigms. The model undergoes thousands of steps of continued RL training to reach the final checkpoints.
For reasoning and agentic tasks, the reward structure combines rule-based outcome rewards, length penalties, and language consistency rewards. General tasks employ generative reward models where each prompt has custom evaluation rubrics. This mixed reward strategy allows the model to optimize for both verifiable correctness (in mathematical or coding tasks) and nuanced quality (in open-ended generation).
Critical Modifications for RL Stability at Scale
Scaling reinforcement learning to this magnitude of compute investment requires addressing fundamental stability challenges. DeepSeek introduces four key modifications to the standard GRPO algorithm that prove essential for stable training.
1. Unbiased KL Estimate with Domain-Specific Regularization
KL divergence regularization is a standard technique in policy gradient methods to prevent the learned policy from deviating too far from a reference policy, maintaining distributional stability3538. However, standard KL estimators can introduce systematic bias in off-policy settings when sampled tokens have substantially different probabilities under the current versus reference policy.
DeepSeek corrects this through an unbiased KL estimate using importance sampling, weighting the standard KL terms by the ratio to account for the distributional shift between the sampling and current policies. This correction eliminates systematic estimation errors, facilitating stable convergence. Additionally, different domains benefit from varying KL regularization strengths. Mathematics, for instance, often achieves improved performance with relatively weak KL penalties or none at all—allowing the model greater flexibility to explore novel reasoning strategies.
2. Off-Policy Sequence Masking
Large-scale RL systems generate rollout data in batches that are split into mini-batches for multiple gradient updates35, introducing inherent off-policy behavior. Implementation differences between optimized inference frameworks (used for data generation) and training frameworks further exacerbate this divergence. To maintain stability, DeepSeek introduces a masking strategy that filters out sequences with significant policy divergence:
The masking function equals 0 when the advantage is negative and the average log-probability ratio exceeds threshold ; otherwise it equals 1.
Critically, masking applies only to sequences with negative advantages (where the advantage estimate is less than zero). The intuition is clear: the model benefits most from learning from its own mistakes, but highly off-policy negative samples can mislead the optimization process. This selective masking substantially improves training stability in scenarios that would otherwise exhibit instability.
3. Keep Routing for Mixture-of-Experts
Mixture-of-Experts architectures2737 activate only a subset of expert modules during inference, improving computational efficiency. However, discrepancies between inference and training frameworks, compounded by policy updates, can cause inconsistent expert routing even for identical inputs. These abrupt shifts in the active parameter subspace destabilize optimization and exacerbate off-policy issues.
DeepSeek addresses this by preserving the expert routing paths used during sampling and enforcing identical routing during training. This "Keep Routing" operation ensures that the same expert parameters are optimized, maintaining consistency between data generation and learning. This technique has been essential for MoE model stability since DeepSeek-V3-0324.
4. Keep Sampling Mask for Top-p Consistency
Top-p (nucleus) sampling39 enhances response quality by truncating extremely low-probability tokens. While beneficial for sample quality, this truncation creates a mismatch between the action spaces of the sampling policy and training policy, violating importance sampling principles and destabilizing training.
The solution: preserve the truncation masks from sampling and apply them identically during training, ensuring both policies share the same action subspace. This "Keep Sampling Mask" strategy, combined with top-p sampling, effectively preserves language consistency throughout RL training.
V3.2 versus V3.2-Speciale: Divergent Training Objectives
The standard DeepSeek-V3.2 model integrates reasoning, agent, and human alignment data, optimizing the trade-off between performance and token efficiency. This balanced approach targets everyday deployment scenarios where inference cost and latency matter.
DeepSeek-V3.2-Speciale takes a different path. Trained exclusively on reasoning data with a significantly reduced length penalty, Speciale is optimized to maximize problem-solving capability without constraint on token budget. The training additionally incorporates the dataset and reward methodology from DeepSeekMath-V2, specifically enhancing capabilities in complex mathematical proofs.
The result: V3.2 delivers GPT-5-level reasoning with superior token efficiency for general use, while Speciale achieves Gemini-3.0-Pro-level performance on the most challenging reasoning tasks—reaching gold medal thresholds in IMO 2025, IOI 2025, and ICPC World Finals—at the cost of higher token consumption.
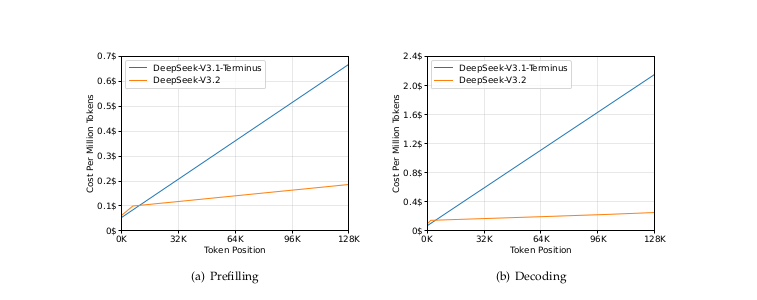
Figure 5: Inference cost comparison demonstrating the efficiency gains from the sparse attention architecture. Compared to the dense attention baseline (DeepSeek-V3.1-Terminus), V3.2 achieves dramatically lower costs per million tokens during both prefilling (processing input context) and decoding (generating output).
Large-Scale Agentic Training Pipeline
The third pillar of DeepSeek V3.2's design addresses the generalization bottleneck in agentic scenarios. While recent work has demonstrated that language models can be adapted for tool use and multi-step reasoning404142, open-source models typically struggle with robustness across diverse task distributions and environmental variations. Benchmark evaluations on AgentBench43, Tau-Bench44, and WebArena45 reveal substantial performance gaps between open and closed systems. DeepSeek's solution is ambitious in scope: an automated pipeline that synthesizes 1,827 distinct task environments and generates over 85,000 complex prompts spanning search, coding, reasoning, and general planning domains.
This agentic training infrastructure represents a fundamental shift from hand-crafted task datasets4647 toward scalable, automatic environment generation—an approach with precedent in robotics48 and game-playing domains49. The diversity of tasks—combined with verification mechanisms that ensure each task is challenging yet automatically gradable—enables reinforcement learning on agentic behaviors at unprecedented scale.
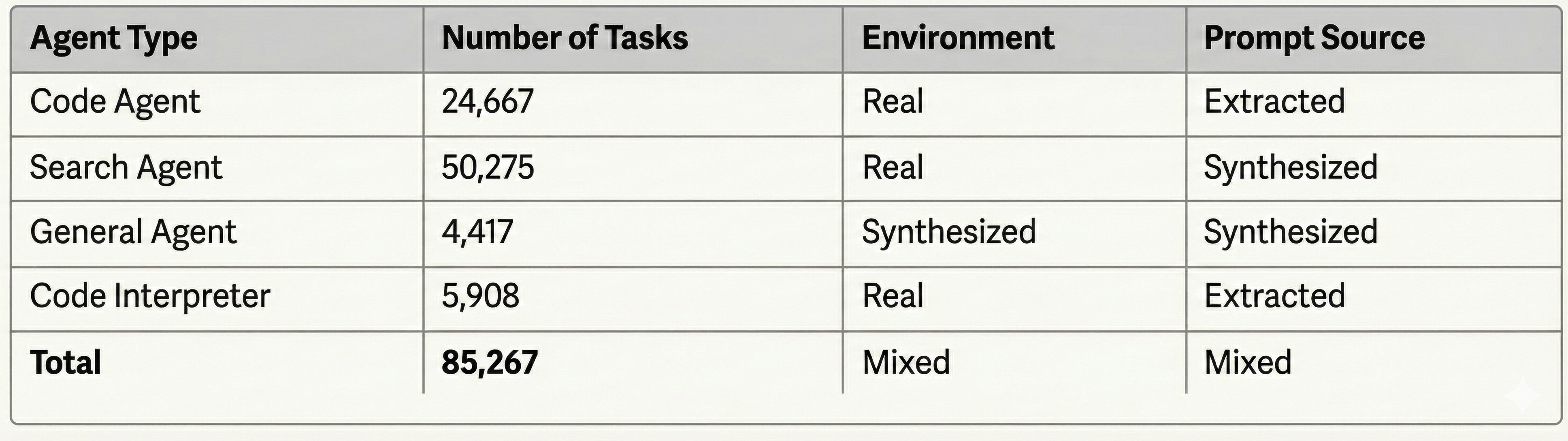
Table 3: Agentic Task Distribution across the four agent types in DeepSeek V3.2's training pipeline.
The distribution reveals a strategic emphasis on search and code agents—domains where verifiable correctness enables effective RL training. Notably, three of the four agent types employ real-world tools (web search APIs, GitHub repositories, Jupyter notebooks), while prompts are either extracted from internet sources or synthetically generated to ensure diversity without privacy concerns.
Search Agent: Multi-Agent Data Generation Pipeline
The search agent training data is generated through a sophisticated multi-agent pipeline designed to produce both factually reliable and practically helpful responses. The process begins by sampling informative long-tail entities across diverse domains from large-scale web corpora—entities that require active information gathering rather than simple knowledge retrieval.
A question-construction agent explores each entity using configurable search depth and breadth parameters, consolidating discovered information into question-answer pairs. The key to quality is heterogeneity: multiple answer-generation agents with different model checkpoints and system prompts produce diverse candidate responses for each question. A verification agent equipped with search capabilities then validates all answers through multiple passes, retaining only samples where the ground-truth answer is correct and all candidate answers are verifiably incorrect.
This filtering ensures the training data presents genuinely challenging search tasks where naive responses fail verification. The data spans multiple languages, domains, and difficulty levels. To complement these verifiable samples and reflect real-world usage patterns, the dataset is augmented with filtered instances from existing helpful RL datasets where search tools provide measurable benefits.
The reward structure employs a hybrid approach: detailed evaluation rubrics across multiple quality dimensions are scored by generative reward models. This enables optimization for both factual reliability (verifiable correctness against ground truth) and practical helpfulness (addressing the user's underlying information need).
Code Agent: Large-Scale Executable Environments
The code agent training infrastructure leverages millions of issue-Pull Request pairs mined from GitHub to create executable software engineering environments. Each environment represents a real software bug or feature request with an associated fix, enabling outcome-based reward evaluation—a substantial advantage over reward models requiring human annotation50 or proxy metrics of uncertain validity51. The ability to execute code and run tests provides unambiguous ground truth for many (though not all) software engineering tasks.
The construction pipeline applies rigorous filtering using both heuristic rules and LLM-based quality judgments. Valid entries must contain: (1) a reasonable issue description, (2) a correlated gold patch (the correct fix), and (3) a test patch for validation. An automated environment-setup agent—itself powered by DeepSeek-V3.2—handles the complex task of building executable environments: installing packages, resolving dependencies, and executing tests.
Test results are standardized in JUnit format, enabling consistent parsing across eight programming languages: Python, Java, JavaScript, TypeScript, C, C++, Go, and PHP. The validation criteria are strict: an environment is deemed successfully built only when applying the gold patch produces a non-zero count of false-to-positive test cases (confirming the issue is fixed) and zero pass-to-fail cases (confirming no regressions are introduced).
This pipeline successfully constructed tens of thousands of reproducible issue resolution environments, providing the code agent with diverse, verifiable training tasks that mirror real-world software engineering challenges.
Code Interpreter Agent: Leveraging Execution for Reasoning
The code interpreter agent addresses complex reasoning tasks that benefit from computational assistance. Using Jupyter Notebook as the execution environment, the training dataset comprises problems spanning mathematics, logic, and data science—domains where verification through computation is natural.
Unlike pure reasoning tasks where the model must solve problems entirely through language, code interpreter tasks allow the model to write and execute code as part of the solution process. This mirrors human problem-solving behavior: when faced with complex calculations, symbolic manipulations, or data analysis, we naturally reach for computational tools. Training the model to leverage code execution for reasoning tasks teaches a generalizable skill applicable across domains.
General Agent: Automatic Environment Synthesis
Perhaps the most innovative component is the general agent synthesis pipeline—an automated system that generates entirely new task environments without human specification. The goal is to create tasks that are "hard to solve but easy to verify," enabling automatic reward computation during RL training.
The synthesis workflow operates in stages:
-
Environment Initialization: Given a task category (e.g., trip planning), an agent equipped with bash and search tools generates or retrieves relevant data from the internet, populating a sandbox database.
-
Toolset Construction: The agent synthesizes a set of task-specific tools, each implemented as a callable function. These tools provide the interface through which the task must be solved.
-
Task and Verifier Generation: The agent proposes an initial simple task along with solution and verification functions implemented in Python. Critically, the solution function is restricted to invoking tool functions or performing logical computations—it cannot directly access the database or call arbitrary functions. This ensures the task can only be solved through the provided tool interface.
-
Iterative Difficulty Scaling: The agent progressively increases task difficulty, updating solution and verification functions accordingly. If the current toolset proves insufficient, the agent augments it with additional tools.
-
Validation and Filtering: The pipeline retains only tasks where the solution passes verification. Final filtering through RL training keeps only environments with non-zero pass@100, ensuring tasks remain challenging for the model.
This process yields thousands of environment, tools, task, verifier tuples. After RL training and filtering, 1,827 environments with 4,417 total tasks remain in the final dataset.
I'm planning a three-day trip starting from Hangzhou, and I need help creating an itinerary from October 1st to October 3rd, 2025. A few important requirements: I don't want to repeat any cities, hotels, attractions, or restaurants during the entire trip. Also, please make sure that every hotel, restaurant, and attraction you recommend is actually located in the city where I'll be staying that day. One more thing about the second day - I'm trying to be smart about my budget. If I end up booking a luxury hotel that costs 800 CNY or more per night, then I need to be more careful with other expenses: my total spending on both restaurants (lunch and dinner) should stay under 350 CNY, both restaurants should be rated at least 4.0 stars, and the afternoon attraction ticket needs to be less than 120 CNY. If the hotel on day 2 is in the mid-to-high range (500-800 CNY), then I have a bit more flexibility - I just need to make sure at least one of my restaurant choices is rated 4.0 or higher, and the attraction ticket should be below 180 CNY. For more affordable hotels (200-500 CNY range), I only need to ensure that at least one restaurant has a rating of 3.2 or above. Can you help me put together this itinerary?
| Function Name | Description |
|---|---|
get_all_attractions_by_city(city) | Get all attractions for given city. |
get_all_cities() | Get all cities from the database. |
get_all_hotels_by_city(city) | Get all hotels for given city. |
get_all_restaurants_by_city(city) | Get all restaurants for given city. |
get_city_by_attraction(attraction) | Get city for given attraction name. |
get_city_by_hotel(hotel) | Get city for given hotel name. |
get_city_by_restaurant(restaurant) | Get city for given restaurant name. |
get_city_transport(city) | Get all intra-city transport options for given city. |
get_infos_by_attraction(info_keywords, attraction) | Get specified infos for given attraction. |
get_infos_by_city(info_keywords, city) | Get specified infos for given city. |
get_infos_by_hotel(info_keywords, hotel) | Get specified infos for given hotel. |
get_infos_by_restaurant(info_keywords, restaurant) | Get specified infos for given restaurant. |
get_inter_city_transport(from_city, to_city) | Get all transports between given city pair. |
get_weather_by_city_date(city, date) | Get weather for given city-date pair. |
submit_result(answer_text) | Submit the final answer content. |
The Diversity Strategy
A critical insight underlies the entire agentic training pipeline: robustness emerges from diversity in both tasks and agent configurations. The search agent employs heterogeneous answer-generation agents with different model checkpoints and system prompts. The general agent synthesis process produces environments spanning vastly different domains and constraint structures. This diversity ensures the model encounters varied problem-solving scenarios during training, preventing overfitting to narrow task distributions.
The result is a model that demonstrates robust generalization across agentic benchmarks. The training infrastructure scales to over 85,000 tasks across four agent types, providing the reinforcement learning process with the breadth of experience necessary to develop genuinely capable agentic behaviors rather than memorized solutions to specific task families.
Thinking in Tool-Use: Context Management for Extended Reasoning
A fundamental challenge emerges when combining extended reasoning chains with agentic tool use: context windows, even at 128K tokens, become a limiting factor. As agents perform multiple tool calls while maintaining reasoning traces, the accumulated context can exhaust available memory, prematurely truncating the problem-solving process. This bottleneck directly constrains the realization of test-time compute scaling—the ability to invest additional inference-time computation for improved solutions5253.
DeepSeek V3.2 introduces two innovations to address this challenge: a thinking retention mechanism specifically designed for tool-calling scenarios, and adaptive context management strategies that enable continued reasoning beyond context limits.
Thinking Retention: Learning from DeepSeek-R1
DeepSeek-R1 demonstrated that incorporating explicit thinking processes significantly enhances problem-solving capability on complex tasks54. The natural approach would be to replicate R1's strategy in tool-calling scenarios. However, R1's context management—discarding all reasoning content upon receiving the second round of messages—proves severely inefficient for agentic workflows.
The inefficiency is straightforward: discarding reasoning traces forces the model to redundantly re-reason through the entire problem context after each tool call. In multi-step agentic tasks requiring numerous tool interactions, this repeated reasoning consumes enormous token budgets without providing commensurate benefits. The model essentially "forgets" its reasoning and must reconstruct it from scratch with each tool result.
DeepSeek V3.2 implements a more sophisticated retention strategy tailored specifically for tool-calling scenarios (Figure 6). The key insight: distinguish between different types of context updates.
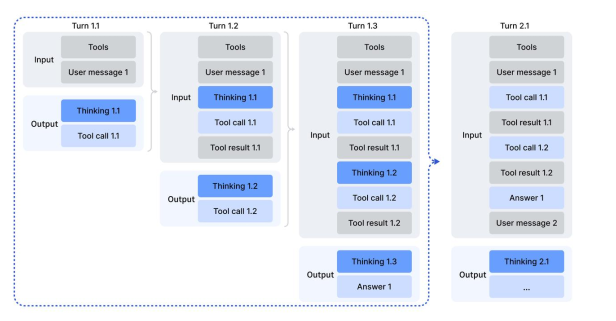
Figure 6: Thinking retention mechanism in tool-calling scenarios. The model retains reasoning traces across tool calls within a single problem-solving episode, only discarding when a new user message arrives.
Figure 6 illustrates the retention mechanism across multiple interaction turns. In Turn 1.1, the model receives a user message and produces thinking (extended reasoning) followed by a tool call. The tool result returns in Turn 1.2, but critically, no new user message has arrived—only a tool-related message (the tool output) has been appended. Under DeepSeek V3.2's strategy, the historical reasoning content is retained. The model can then continue thinking in Turn 1.2, building upon its prior reasoning without reconstruction. This pattern continues through Turn 1.3 as additional tool calls are made and their results integrated.
Only when a completely new user message arrives (Turn 2.1) does the model discard the historical reasoning traces. At this point, the previous problem context is genuinely concluded, and a fresh reasoning process begins. Importantly, even when reasoning is discarded, the history of tool calls and their results remains preserved—providing the model with a factual record of actions taken without the token overhead of full reasoning traces.
This retention strategy dramatically reduces token consumption in agentic workflows. Rather than reasoning from scratch after each tool interaction, the model maintains reasoning continuity across multiple tool calls within a single problem-solving episode. The efficiency gains are substantial: instead of re-reasoning through the problem N times for N tool calls, the model reasons incrementally, updating its thinking based on new tool results.
Adaptive Context Management Strategies
Even with optimized thinking retention, exceptionally long agentic sessions can approach context limits. DeepSeek implements three context management strategies that trigger automatically when token usage exceeds 80% of the 128K context window:
-
Summary: The model summarizes the overflowed trajectory—condensing the reasoning trace and tool call history into a compact representation—then re-initiates the rollout from this summarized state. This preserves problem context while freeing tokens for continued progress.
-
Discard-75%: The first 75% of tool call history is removed from context. This aggressive pruning retains only recent interactions, operating under the assumption that recent tool results are most relevant for immediate next steps.
-
Discard-all: All previous tool call history is reset, providing maximum context space. This strategy is analogous to Anthropic's "new context" tool, essentially starting fresh while maintaining the core problem specification.
Evaluation on the BrowseComp benchmark—a challenging web navigation and information gathering task—reveals clear performance characteristics. The Summary strategy extends average interaction steps from 140 to 364, improving accuracy from 53.4% to 60.2%. However, the token overhead of generating summaries limits overall efficiency.
The Discard-all strategy achieves the best balance, reaching 67.6% accuracy while maintaining favorable token efficiency. Surprisingly, completely resetting the tool call history often performs better than partial retention, suggesting that models can effectively recover problem context from the core task specification without requiring complete interaction history.
These context management strategies enable serial scaling of test-time compute: the model can continue problem-solving beyond single-context-window solutions, investing additional computation to tackle harder problems. This complements parallel scaling approaches (sampling multiple independent trajectories) and provides an additional axis for trading compute against solution quality.
Cold-Start: Integrating Reasoning with Tool-Use
A practical challenge arises during training: how to integrate reasoning capabilities (trained on non-agentic data) with tool-use capabilities (trained on agentic data without extended reasoning)? DeepSeek employs a "cold-start" mechanism based on carefully designed prompting that instructs the model to incorporate tool execution within the reasoning process.
The approach relies on the model's ability to follow explicit instructions. Three distinct system prompts handle different scenarios:
-
Reasoning-only tasks: System prompt explicitly requests reasoning before the final answer, using special tags <think></think> to delineate the reasoning path
-
Non-reasoning agentic tasks: System prompt contains guidance for tool calling without extended reasoning
-
Reasoning + tool-use tasks: Combined system prompt instructs the model to incorporate multiple tool calls within its reasoning process
While this cold-start mechanism may not produce perfectly robust reasoning-tool integration initially, it generates occasional correct trajectories. These serve as seed examples for subsequent reinforcement learning stages, which refine and stabilize the integrated behavior. The RL process amplifies successful patterns while filtering out failures, ultimately producing a model that seamlessly combines extended thinking with tool use.
This integration represents a significant capability advancement. V3.2 becomes the first model to natively support thinking mode within tool-calling scenarios—a design choice that distinguishes it from models where reasoning and tool use remain separate, disconnected capabilities.
Important Caveat for Agent Frameworks
Certain agent frameworks simulate tool interactions via user messages rather than dedicated tool message types. In such architectures, each tool result appears as a new user message, triggering the context management rule that discards historical reasoning. For these frameworks, DeepSeek recommends utilizing non-thinking models, as the thinking retention mechanism cannot provide benefits when the framework itself forces reasoning trace discard.
This design decision reflects a principled stance: context management strategies must align with the actual message structure of the interaction protocol. Rather than attempting to handle all possible frameworks universally, DeepSeek optimizes for frameworks that properly distinguish tool messages from user messages, providing maximum efficiency in those settings while offering non-thinking models as alternatives for incompatible frameworks.
Results & Benchmarks
Competition Performance: Gold Medal Achievements
DeepSeek-V3.2-Speciale achieves gold-medal-level performance across four elite 2025 competitions without targeted training for these specific tasks.
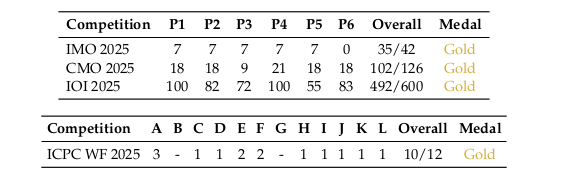
Table 4: Top-Tier Competition Results. DeepSeek-V3.2-Speciale achieves gold-medal thresholds across IMO, CMO, IOI, and ICPC World Finals—the first open-source model to reach this level.
The ICPC World Finals result is particularly notable: DeepSeek-V3.2-Speciale ranked 2nd among all competitors, solving 10 out of 12 problems in this premier programming competition. The IOI 2025 result places the model at 10th globally—a remarkable achievement for a general-purpose model competing against specialized human competitors.
Benchmark Comparisons: Matching Frontier Performance
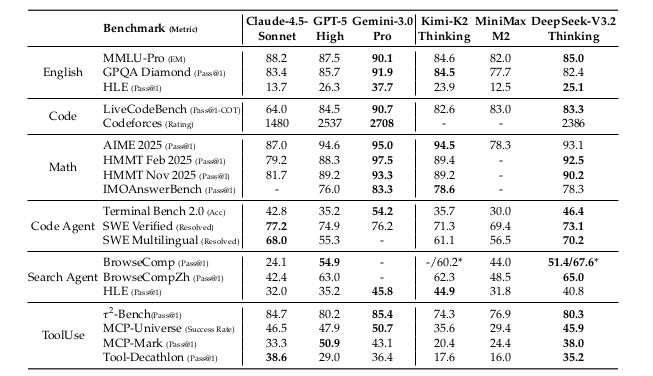
Table 5: DeepSeek-V3.2 vs. Closed and Open Models. Comprehensive benchmark results comparing DeepSeek-V3.2 against closed-source (Claude-4.5-Sonnet, GPT-5 High, Gemini-3.0 Pro) and open-source models with thinking capabilities (Kimi-K2 Thinking, MiniMax V2). The τ²-Bench results are computed by averaging across all categories. BrowseComp performance: 51.4 (standard) / 67.6 (with context management technique).
Key observations:
- Math reasoning: Within 1-2% of GPT-5 High and Gemini-3.0 Pro on AIME 2025, HMMT competitions
- Code generation: Codeforces rating of 2386, competitive with frontier models
- Agentic tasks: Strong performance on Terminal Bench 2.0 (46.4%), SWE-Multilingual (70.2%)
- Tool use: Matches or exceeds closed-source models on multiple benchmarks
Token Efficiency: Performance Without Cost Penalty
While V3.2-Speciale maximizes reasoning depth, the standard V3.2 model optimizes the performance-efficiency trade-off for everyday deployment.
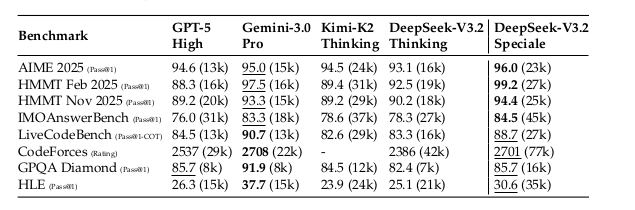
Table 6: Reasoning Model Performance and Efficiency. Values show accuracy and average output tokens in thousands. V3.2-Speciale achieves the highest accuracy on most benchmarks, but requires 1.5-2× more tokens than standard V3.2.
The pattern is clear: V3.2-Speciale achieves the highest accuracy on most benchmarks, but requires 1.5-2× more tokens than standard V3.2. The standard model delivers near-frontier performance at significantly lower token costs—HMMT Feb 2025: 92.5% with 19k tokens versus Gemini-3.0 Pro's 97.5% with 16k tokens represents a 5% accuracy gap for comparable token budgets.
Synthetic Data Generalization: Validation Through Ablation
A critical question: Do synthetically generated agentic tasks provide genuine learning signal, or do they merely teach pattern matching on artificial distributions?
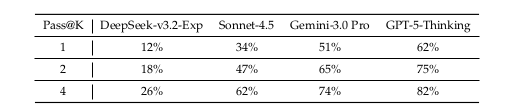
Table 7: Synthetic Task Difficulty Assessment. Evaluated on 50 randomly sampled synthetic general agent tasks, even frontier closed-source models achieve only 62% accuracy at Pass@1.
Evaluated on 50 randomly sampled synthetic general agent tasks, even frontier closed-source models achieve only 62% accuracy at Pass@1. The synthesis model itself (DeepSeek-V3.2-Exp) solves just 12% on first attempt, confirming the tasks are genuinely challenging rather than trivially solvable by the generating model.
Figure 7 demonstrates generalization through RL training curves. When DeepSeek-V3.2-SFT is trained exclusively on synthetic general agent data (no code or search environments), performance improves substantially across multiple real-world benchmarks:
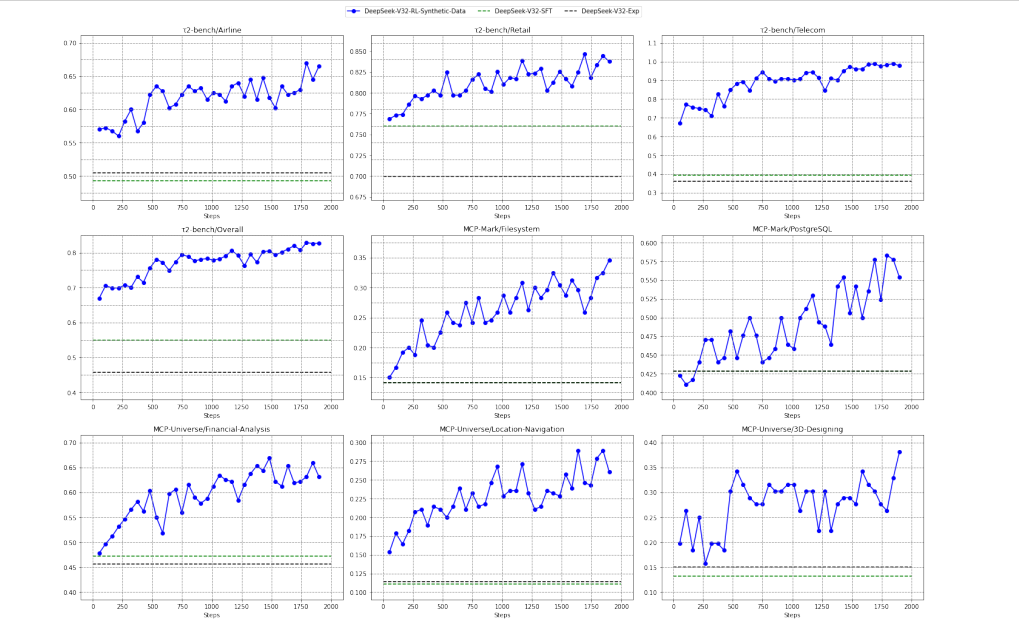
Figure 7: RL training of DeepSeek-V3.2-SFT using exclusively synthetic general agent data. All benchmarks show monotonic improvement, validating synthetic data transfer to real-world tasks.
- τ²-Bench: Steady improvement from ~0.54 to ~0.70 over 2000 training steps
- MCP-Mark: Growth from ~0.20 to ~0.35, with continued upward trajectory
- MCP-Universe: Consistent gains reaching ~0.50 by training completion
- Overall generalization: All benchmarks show monotonic improvement, validating synthetic data transfer
Critically, the baseline models trained only on code and search scenarios (dotted lines) show no improvement on these general agentic benchmarks, confirming that the synthetic general agent data provides unique learning signal beyond domain-specific training.
Context Management: Scaling Test-Time Compute
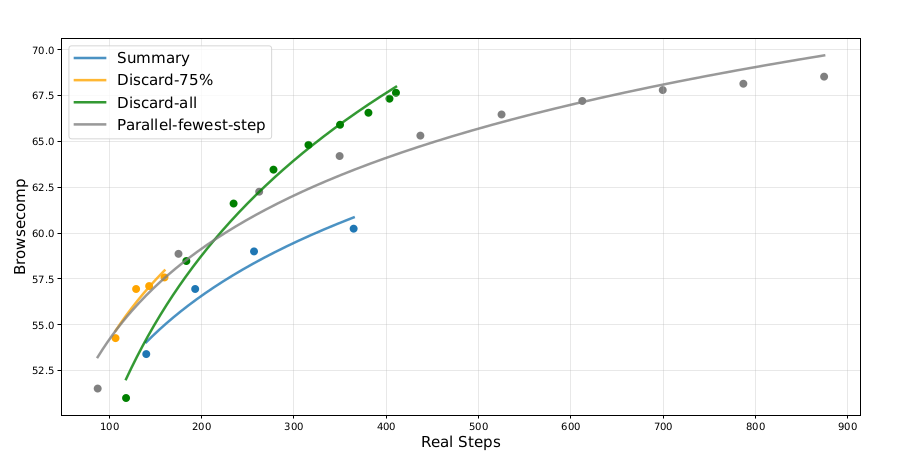
Figure 8: Context management strategy comparison on BrowseComp. Accuracy plotted against number of real execution steps, demonstrating the effectiveness of different pruning strategies for scaling test-time compute.
Figure 8 quantifies the effectiveness of different context management strategies on BrowseComp, plotting accuracy against the number of real execution steps (a proxy for computational budget).
The results are striking:
- Discard-all (green): Achieves 67.6% accuracy at ~350 real steps, following a steep improvement curve before plateauing
- Parallel-fewest-step (gray): Reaches similar final accuracy (~68%) but requires significantly more total compute
- Discard-75% (yellow/orange): Shows intermediate performance, reaching ~58% at 200 steps
- Summary (blue): Extends steps from 140 → 364 but achieves only 60.2% accuracy—better than baseline but less efficient than Discard-all
The Discard-all strategy demonstrates the best efficiency-accuracy trade-off: aggressive context pruning allows the model to continue problem-solving with fresh context space, achieving near-parallel-scaling performance through serial computation. This validates the context management approach as a viable method for scaling test-time compute in agentic workflows where context exhaustion is a primary bottleneck.
Closing Thoughts
The DeepSeek V3.2 release represents a watershed moment for open-source AI. Through principled architectural innovations—DeepSeek Sparse Attention reducing computational complexity from quadratic to near-linear—combined with unprecedented post-training investment exceeding 10% of pre-training compute, and an automated agentic training pipeline synthesizing 1,827 task environments, DeepSeek has demonstrated that open-source models can achieve genuine frontier performance. The gold-medal results in IMO 2025, IOI 2025, and ICPC World Finals aren't incremental progress; they're evidence that the performance gap between open and closed systems has fundamentally narrowed.
The implications ripple across multiple dimensions. For developers, V3.2 provides access to GPT-5-level reasoning capabilities at 24× lower cost—enabling applications previously infeasible due to inference economics. For industry, the 29× cost advantage relative to Gemini-3.0 Pro shifts deployment calculations and competitive dynamics. Startups in developing markets, academic research groups, and resource-constrained organizations gain access to capabilities previously restricted to well-capitalized entities. For research, complete open weights under MIT license enable reproducibility, architectural experimentation, and validation of claims—the foundational requirements for scientific progress.
The momentum shift is undeniable. The narrative that open-source models lag proprietary systems by six to eight months has been directly challenged. In several domains—particularly in competition mathematics and programming—open-source has not merely caught up but exceeded closed alternatives. Silicon Valley companies increasingly rely on open models, validating the technical and economic viability of the open-source approach. DeepSeek V3.2 accelerates this trajectory, potentially catalyzing a cascade of derived models, novel applications, and further architectural innovations.
A Critical Omission: Safety Considerations
However, a troubling gap exists in the technical report: across more than 20 pages of detailed architectural descriptions, training methodologies, and benchmark evaluations, there is virtually no discussion of model safety or safety-related benchmarks. For a 685-billion parameter model achieving frontier capabilities and released with complete open weights, this omission is significant.
Preliminary evaluations reveal concerning vulnerabilities55. The model is susceptible to common adversarial attacks that expose system prompts, generate detailed instructions for producing biological weapons (anthrax synthesis, smallpox cultivation in laboratory settings), and provide responses to politically sensitive queries including topics typically censored by Chinese content moderation systems (Xinjiang detention facilities, Tiananmen Square events). While these vulnerabilities are not unique to DeepSeek—many frontier models exhibit similar weaknesses—the combination of frontier capabilities, complete open-source release, and absent safety documentation creates meaningful risk.
The open-source community has a responsibility to address safety considerations with the same rigor applied to performance optimization. This includes:
-
Adversarial robustness evaluations: Systematic testing against jailbreaking techniques, prompt injection attacks, and context manipulation
-
Harmful content generation: Benchmarks measuring propensity to generate CBRN (chemical, biological, radiological, nuclear) weapon information, illegal drug synthesis, or other dangerous content
-
Bias and fairness assessments: Evaluation across demographic dimensions, political orientations, and cultural contexts
-
Refusal behavior analysis: Understanding when and how the model declines harmful requests versus legitimate boundary cases
-
Alignment persistence under fine-tuning: Whether safety guardrails remain intact when the model is further trained by downstream users
The absence of these evaluations in the technical report doesn't necessarily indicate the DeepSeek team neglected safety during development. It may reflect different prioritization, resource constraints, or cultural differences in what constitutes publishable research. However, for the broader community deploying these models in production systems, safety documentation is not optional—it's essential for responsible deployment.
The Path Forward
The tension between open access and safety considerations is real but not insurmountable. The open-source AI community must develop robust safety evaluation frameworks that parallel the sophistication of performance benchmarks. DeepSeek's technical achievements—the architectural innovations, training methodologies, and performance results—are genuinely impressive and advance the field substantially. The model's capabilities will enable valuable applications across education, research, and industry.
But capability without safety consideration is incomplete. As the community builds upon DeepSeek V3.2's foundations, incorporating comprehensive safety evaluations into future releases should become standard practice. The goal is not to restrict access but to provide deployment guidance: understanding model limitations, documenting failure modes, and enabling informed risk assessment.
DeepSeek V3.2 demonstrates that open source can achieve frontier performance through principled innovation and strategic resource allocation. The next challenge is demonstrating that open source can also achieve frontier safety—developing models that are not only capable but also robust, aligned, and trustworthy. The technical foundations are promising. The safety infrastructure needs to catch up.
The era of reasoning-first, agent-oriented models has arrived. It's open source. And it demands that we take safety as seriously as we take performance.